Robots.txt – это текстовый файл, расположенный в корневой папке сайта, содержащий в себе набор инструкций по обходу страниц сайта для роботов поисковых систем. В данной статье мы рассмотрим, какие директивы и спецсимволы используются, расскажем, как закрыть от индексации страницы сайта, составить данный файл правильно, приведем несколько шаблонов robots.txt для популярных CMS.
Для чего нужен файл
Роботы-краулеры поисковых систем перед посещением страницы обращаются к данному файлу, проверяя, доступна данная страница или нет. В файле содержатся все инструкции для роботов при сканировании сайта (индексация, запрет индексации, «склейка» параметров для Яндекса, расположение карты сайта. При запрете индексации поисковые системы не проиндексируют страницу. Это позволяет закрыть от индексации.
Именно по ключевикам поисковые системы определяют:
- дубли страниц;
- служебные страницы;
- малоценные страницы для пользователя и др.
Корректной настройке данного файла следует уделять внимание, т.к. при наличии ошибок в данном файле страницы, разделы или весь сайт может оказаться закрытым от индексации.
Стоит понимать что данный файл является «рекомендательным», а не набором обязательных требований. Например, в Google Search Console вы можете встретить ошибку: «Проиндексировано, несмотря на блокировку в файле robots.txt».
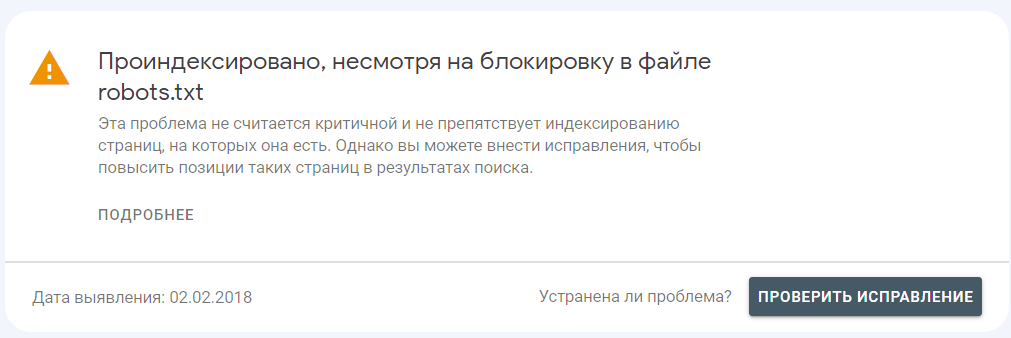
В данном случае роботы поисковой системы могут индексировать страницы сайта, имеющие ссылки с внешних источников.

В случае если вам необходимо достоверно закрыть страницу от индексации в Google, требуется вместо запрета в роботсе использовать мета-тег robots в коде страницы (при запрете индексации в robots.txt робот может не просканировать данный тег). В разделе
HTML-кода страницы необходимо добавить мета-тег robots с значениями атрибута content = "noindex, nofollow":<meta name="robots" content="noindex, nofollow"/>Требования к файлу robots.txt
- Название: только "robots.txt" в строчном регистре.
- Формат: txt
- Размещение: только в корневом каталоге, например https://skobeeff.com/robots.txt (для поддоменов основного сайта – в корневых каталогах поддоменов, например https://seo.skobeeff.com/robots.txt)
- Отклик: ссылка на файл должна отдавать 200 отклик сервера
- Размер: до 32 КБ
- Количество: в единственном экземпляре
- Язык: латиница (за исключением #комментариев), если сайт имеет кириллические URL, необходимо конвертировать их в Punycode (кириллический адрес – xn-- -8sbmbdnaabkfeka6elki7h)
- Порядок: каждая директива должна начинаться с новой строки
Директивы файла robots.txt
- User-agent *
Определяет поискового робота, к которому относятся правила в группе - Disallow
Запрещает индексирование разделов или отдельных страниц - Allow
Allow Разрешает индексирование разделов или отдельных страниц - Sitemap
Указывает расположение xml файла sitemap - Clean-param
Указывает роботу не индексировать параметрические страницы. Накопленные показатели передаются основному url/ (только Яндекс) - Crawl-delay
Неактуальная директива. Задает роботу скорость обхода сайта. Рекомендуется использовать настройку скорости обхода в Яндекс Вебмастере. (только Яндекс) - Host
Неактуальная директива. Указывает основное зеркало сайта. Рекомендуется использовать 301 редирект. (только Яндекс)
Директива User-agent
Это обязательная директива, указывающая, для каких поисковых роботов будут применяться основные правила, написание под этой директивой – до следующей (за исключением Clean-param и Sitemap, являющихся межсекционными)
- User-agent *
Все поисковые роботы - User-agent: Yandex
Все поисковые роботы Яндекса - User-agent: Googlebot
Все поисковые роботы Google
Всего присутствует большое количество различных ботов поисковых систем и ботов различных приложений. Но в абсолютном большинстве случаев для настройки индексации сайта поисковыми системами рекомендуется использовать основные директивы. Также бытует мнение, что с помощью файла robots.txt можно блокировать ботов сторонних краулеров (например, AhrefsBot, SemrushBot). Но данные боты игнорируют файл robots.txt и такая блокировка бесполезна – эффективно блокировать их в файле .htaccess/
# Запрещаем индексацию для всех роботов, кроме Яндекса и Google:
User-agent: *
Disallow: /
# Задаем отдельные правила для робота Яндекса
User-agent: Yandex #
Disallow: /bitrix/
Disallow: /admin/
Clean-param: utm&from
# Задаем отдельные правила для робота Google
User-agent: Googlebot #
Disallow: /*?utm*
Disallow: /*&utm*
Disallow: /*?from*
Disallow: /*&from*
Пример использования разных правил для роботов
Директива Disallow
Disallow – основная директива, запрещающая сканирование: сайта, раздела, отдельной страницы. В данной директиве чаще всего закрываются:
- служебные страницы;
- конфиденциальные страницы;
- дубликаты страниц;
- параметрические страницы (например, с utm-метками);
- страницы фильтров;
- страницы поиска по сайту;
- логи.
В данном правиле после знака слэша (/) указывается часть URL, на который нужно установить ограничения. Пустое правило разрешает индексировать весь сайт, только слеш (/) запрещает сканировать весь сайт (данное правило рекомендуется использовать для тестовой версии сайта).
User-agent: *
Disallow: # разрешаем все
User-agent: *
Disallow: / # запрещаем индексировать сайт
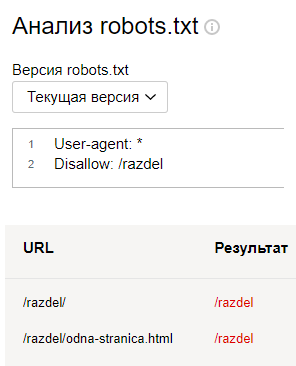
User-agent: *
Disallow: /razdel/ # запрещаем индексировать страницы, в адресе которых есть /razdel/
User-agent: *
Disallow: /razdel/odna-stranica.html #запрещаем индексировать только одну
Пример использования разных правил для роботов
Директива Allow
Allow – директива, разрешающая индексирование, применяется для прописывания исключений из директивы Disallow. Данное правило также поддерживает операторы "*" и "$".
Возвращаясь к нашему сайту из примера выше, добавим еще одну страницу (.../esche-odna-stranica.html). Допустим, нам нужно открыть только одну страницу, правила в роботс будут следующими:
User-agent: *
Disallow: /razdel/
Allow: /razdel/odna-stranica.html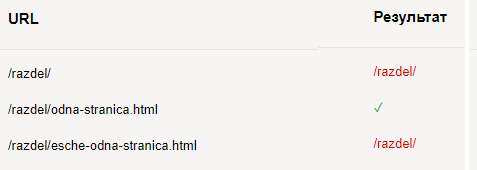
Наиболее часто это используется для разрешения индексации изображений, файлов с CSS и JS в CMS (файлы располагаются в служебных разделах сайта), пример для CMS 1С-Битрикс:
User-Agent: *
Disallow: /bitrix/ # Закрываем служебный раздел
Disallow: /admin/ # Закрываем служебный раздел
Disallow: /upload/ # Закрываем служебный раздел
Allow: */bitrix/*css # Открываем файлы стилей
Allow: */bitrix/*js # Открываем файлы JavaScript
Allow: */upload/*.jpg # Открываем файлы изображений в формате .jpg
Allow: */upload/*.jpeg # Открываем файлы изображений в формате .jpeg
Директива Sitemap
Sitemap содержит в себе ссылку на xml карту(-ы) сайта, необязательная директива – если не используете sitemap.xml, добавлять правило не нужно.
Требования: в данном правиле каждый URL с новой строки, рекомендуется указывать абсолютные URL (полный адрес). Является межсекционным правилом – достаточно указать один раз в файле, без привязки к юзер-агентам, роботы обработают независимо от месторасположения (чаще всего для удобства размещают снизу остальных правил через пустую строку).

Sitemap: https://example.com/sitemap1.xml
Sitemap: https://example.com/sitemap2.xml
Sitemap: https://example.com/sitemap3.xml
Директива Clean-param
Clean-param (только для Яндекса) – директива, позволяющая передать роботу динамические параметры страницы (GET-параметры) с одинаковым контентом, например:
- UTM-метки;
- идентификаторы сессий и пользователей;
- параметры сортировок товаров и многое другое.
Подобные параметрические страницы создают множество дублей основной страницы, мешающие ранжированию страницы в поиске. При использовании данной директивы характеристики пользователей с параметрических страниц будут передаваться основной, непараметрической странице, что при текущем влиянии поведенческих факторов в Яндексе явно выделяет преимущество использования Clean-param вместо закрытия с помощью Disallow. Также краулеры при обходе не будут сканировать URL с параметрами, что снизит нагрузку на сервер и позволит оптимизировать краулинговый бюджет сайта (метрика, определяющая квоту обхода страниц сайта при посещении роботом).
Поисковая система предлагает использовать синтаксис:
Clean-param: p0[&p1&p2&..&pn] [path]
p - параметр;
path - префикс url.
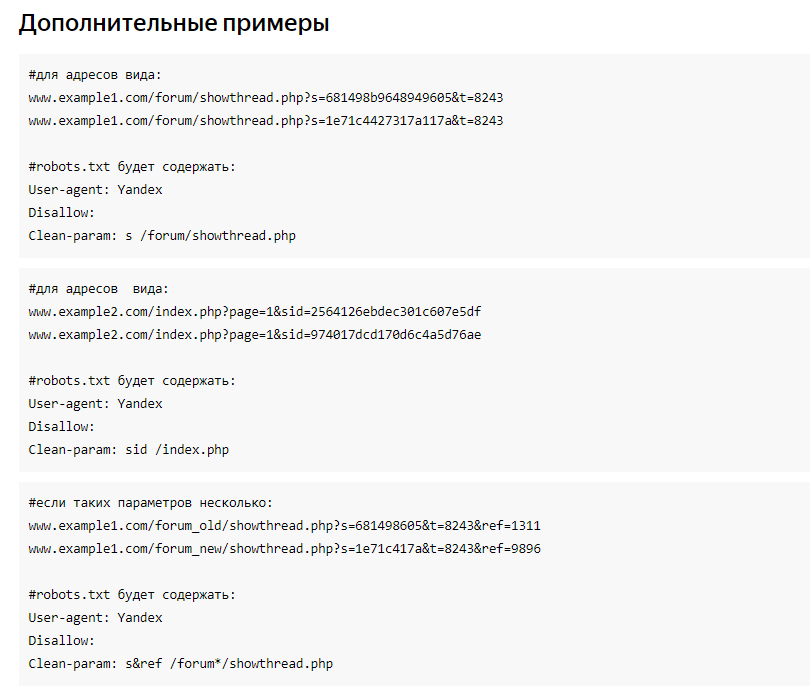
Пример:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrash
В настоящее время доступен более удобный и компактный способ добавления параметров, который в абсолютном большинстве случаев полноценно выполняет свои функции, а именно перечисление параметров в одной строке через амперсанд "&" (до 500 символов в строке).
Clean-param: openstat&utm&from&gclid&yclid&ymclid&tid&cm_idДля проработки параметром можно использовать Яндекс.Метрику, выбираете отчет:
Отчет – Содержание – По параметрам URL
Далее изменяете группировки на:
«Параметр URL» и «Путь (полный) страницы»
В таблице отчета указывается параметр и URL с данным параметром:
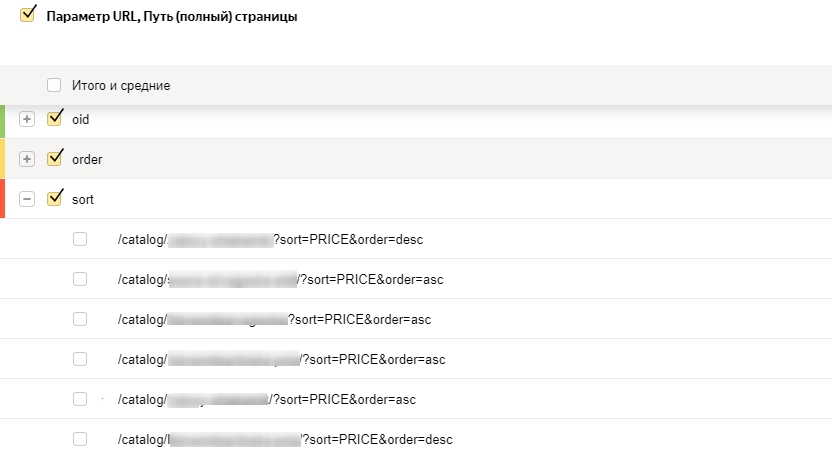
Далее в инструменте Вебмастера Анализ robots.txt вы можете проверить правильность работы данной директивы, добавив URL из отчета метрики. При корректном заполнении в результатах проверки добавляется столбец «URL после учета Clean-Param» с адресом без параметров (если там присутствуют параметры, добавьте их тоже в Clean-Param)
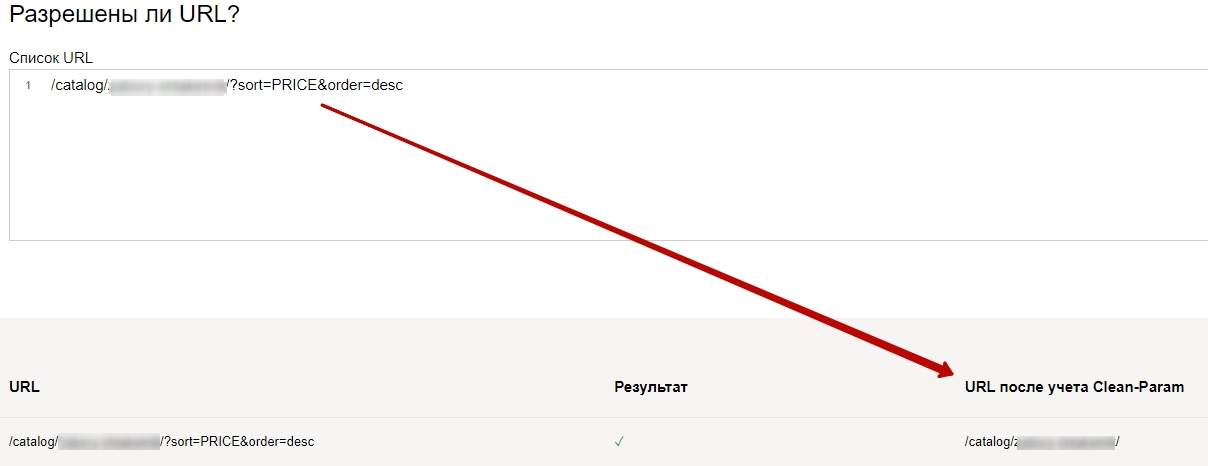
В Google для работы с параметрическими страницами до недавнего времени использовался инструмент «Параметры URL» в Google Search Console, но данный инструмент в настоящее время отключен и, по заверениям от поисковой системы, «в дальнейшем вам не нужно будет ничего делать для определения функции параметров URL на вашем сайте, поисковые роботы Google будут работать с параметрами URL автоматически».
Но если в индексе будут присутствовать подобные URL, рекомендуем закрыть их в Disallow.
Спецсимволы robots.txt ("*" "$" "#")
В файле robots.txt используются символы:
- Символ "*"
Подразумевает любое количество символов после знака - Символ "$"
Указывает окончание строки (противоположность "*") - Символ "#"
Разметка комментариев в файле, после данного символа роботы не обрабатывают содержимое строки, можно использовать кириллицу
Символ * – данный символ используется для сокращения правил и составления регулярных выражений, упрощающих работы.
Рассмотрим пример из битрикса, который уже приводили выше:
User-Agent: *
Disallow: /bitrix/ # Закрываем служебный раздел
Disallow: /admin/ # Закрываем служебный раздел
Disallow: /upload/ # Закрываем служебный раздел
Allow: */bitrix/*css # Открываем файлы стилей
Allow: */bitrix/*js # Открываем файлы JavaScript
Allow: */upload/*.jpg # Открываем файлы изображений в формате .jpg
Allow: */upload/*.jpeg # Открываем файлы изображений в формате .jpeg
В данном примере правило: */upload/*.jpg распространяется для всех файлов формата .jpg, расположенных в разделе */upload/*
При этом данный раздел выделен с обеих сторон символом *, что означает, что до данного раздела может быть любая вложенность (количество папок), после тоже любое количество папок и любые названия файла, но имеющие вхождение .jpg в URL.
При этом в данном случае не обязательно формат является окончанием файла (неявная *).
С помощью данного синтаксиса можно упростить заполнение файла. Допустим, нам нужно закрыть страницу /nenuznaya-stranica/, которая размещена по адресу:
https://example.com/catalog/razdel1/razdel1-1/podrazel-razdel1/nenuznaya-stranica/
User-Agent: *
# закрываем без *:
Disallow: /catalog/razdel1/razdel1-1/podrazel-razdel1/nenuznaya-stranica/
# закрываем с помощью *:
Disallow: */nenuznaya-stranica/
Символ $ указывает окончание строки, выполняя противоположную функцию символу "*".
Пример применения: на сайте из-за ошибок формируются страницы со знаком вопроса на конце URL, нам нужно закрыть подобные страницы, но не закрыть другие страницы, формирующиеся методом GET. В таком случае поможет правило:
User-agent: *
Disallow: /*?$ #действует только на страницы с ? в конце адреса
Также, если нам нужно закрыть весь раздел с отзывами (при генерации для каждого отзыва отдельного адреса), но при этом оставить для индексации листинг отзывов, поможет правило
User-Agent: *
Disallow: /feedback/* # закрываем все
Allow: /feedback/$ # добавляем исключение для одной страницы
Символ # означает комментарии в строке, данные комментарии не воспринимаются поисковыми системами, может быть использована кириллица. Пример:
User-Agent: *
Disallow: / # Продам гараж
Инструменты для проверки и составления файла robots.txt
Для проверки корректности и составления robots.txt в сети представлено много решений, мы рассмотрим стандартные инструменты Анализ robots.txt в Вебмастере Яндекса, Инструмент проверки файла robots.txt в Google Search Console.
Инструмент Яндекса
Анализ robots.txt в Вебмастере Яндекса позволяет загрузить действующий файл, отредактировать, проверить на ошибки синтаксиса, проверить действие для отдельных URL, проверить работу директивы Clean-param.
Для работы добавьте файл (или, если вы залогинены под аккаунтом с доступом к Вебмастеру, роботс подгрузится автоматически).
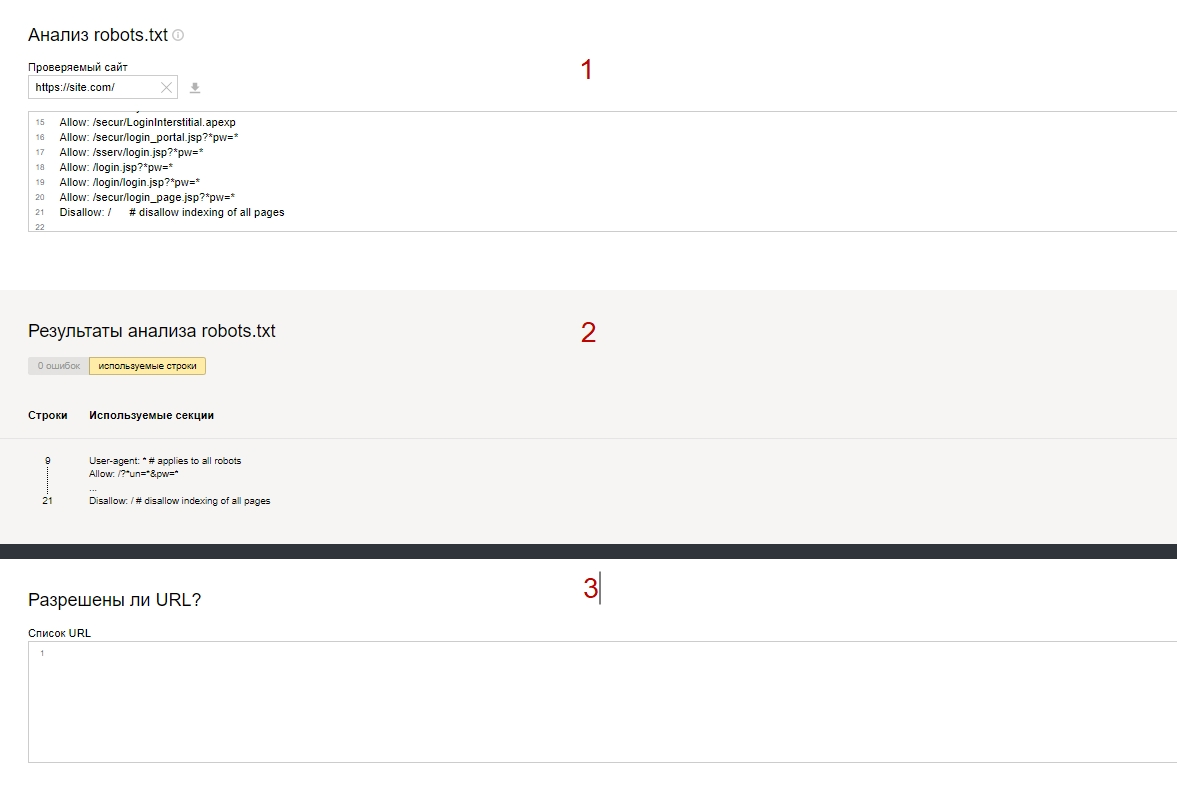
После загрузки файла в данном инструменте доступны три поля:
- окно работы с robots.txt;
- проверка на ошибки (при наличии укажет строку с ошибкой);
- роверка URL – в данном файле вы можете добавить необходимые адреса для проверки, по результатам проверки:
- (a) зеленая галочка – доступен для индексации;
- (b) красный шрифт с правилом из роботса – недоступен с указанием правила.
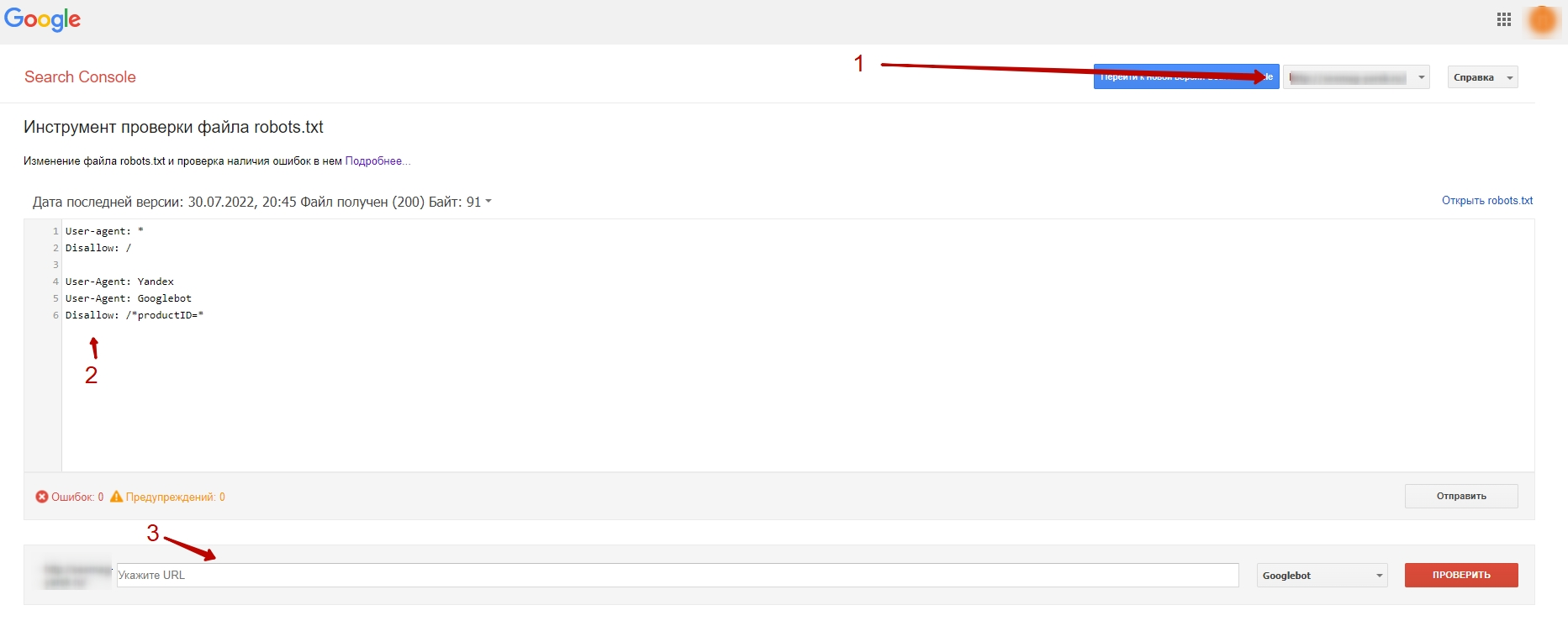
Инструмент Google
Инструмент проверки файла robots.txt в Google Search Console доступен для проверки только при входе под аккаунтом с правами доступа в консоль сайта.
- выбираете сайт, на котором нужно проверить robots.txt;
- изменяете при необходимости правила;
- в окне ниже можно проверить, как срабатывают правила для конкретного адреса:
Пример правильного шаблона robots.txt для CMS
Ниже приведены примеры базового наполнения файлов robots.txt для сайтов на 1С-Битрикс и Вордпресс, но следует понимать, что данные настройки базовые и для реального сайта будут необходимы свои специфические директивы. Если вы планируете использовать данные шаблоны, рекомендуем проверить корректность работы на вашем сайте.
Шаблон robots.txt для сайтов на Bitrix :
User-agent: *
Disallow: /auth*
Disallow: /basket*
Disallow: /order*
Disallow: /personal/
Disallow: /search/
Disallow: /test/
Disallow: /ajax/
Disallow: *index.php*
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: *bitrix*
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*print*
Disallow: /*action*
Disallow: /*register=
Disallow: /*password*
Disallow: /*login=
Disallow: /*type=
Disallow: /*sort=
Disallow: /*order=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: *?arrFilter*
Allow: */bitrix/*css
Allow: */bitrix/*js
Allow: */upload/*.jpg
Allow: */upload/*.JPG
Allow: */upload/*.jpeg
Allow: */upload/*.png
User-agent: Yandex
Disallow: /auth*
Disallow: /basket*
Disallow: /order*
Disallow: /personal/
Disallow: /search/
Disallow: /test/
Disallow: /ajax/
Disallow: *index.php*
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: *bitrix*
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*register=
Disallow: /*password*
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: *?arrFilter*
Allow: */bitrix/*css
Allow: */bitrix/*js
Allow: */upload/*.jpg
Allow: */upload/*.JPG
Allow: */upload/*.jpeg
Allow: */upload/*.png
Clean-param: sort&action&print&order&type&utm&utm_source&openstat&utm&from&gclid&yclid&ymclid&fbclid&tid&cm_id&utm_referrer&etext&block&source
Sitemap: https://example.com/sitemap.xml #указать действительный адрес
Шаблон robots.txt для сайтов на WordPress :
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-param: utm&utm_source&utm_medium&utm_campaign&openstat&from&gclid&yclid&ymclid&fbclid&tid&cm_id&utm_referrer&etext
Sitemap: https://example.com/sitemap.xml #указать действительный адрес

- Для чего нужен файл
- Требования к файлу robots.txt
- Директивы файла robots.txt
- Спецсимволы robots.txt ("*" "$" "#")
- Инструменты для проверки и составления файла robots.txt
- Пример правильного шаблона robots.txt для CMS