Семантика простыми словами
Если вкратце, то семантическое ядро – это просто список запросов, по которым вы хотите, чтобы клиент нашел ваш сайт. Это если очень коротко. Если взглянуть глубже, то семантика – это то, с чего надо начинать любое продвижение и даже создание сайта.
В дальнейшем от правильного сбора ядра будет зависеть многое, как в строительстве домов многое зависит от фундамента!
Как составить семантическое ядро
Допустим, мы с вами решили создать сайт. Пусть это будет сайт по очень вкусной тематике "Торты на заказ".
Для сбора семантического ядра нам потребуется всего лишь один сервис – keys.so. Но предвидим ваши возражения – в статье говорится "не разориться", а минимальный тариф стоит 4900 Р в месяц. Для этого на помощь нам приходит замечательный сайт (который мы для многих задач используем) – kwork.

Итак, давайте начнем
Наша тематика – торты, но не просто торты (ведь мы делаем не кулинарный блог, а собираем семантическое ядро для нашего сайта услуг), а торты на заказ.
Первое, с чего мы начинаем, – вбиваем главный запрос (даже если мы с ним ошибемся, не страшно, потом поправим) "торты на заказ" в поисковую строку и нажимаем "анализировать".

Дальше основная задача – выбрать одного основного конкурента, с которого мы возьмем структуру и семантику. Впоследствии вы можете брать и больше конкурентов, если у вас стоит задача собрать максимально возможную структуру. Но сегодня у нас стоит задача сбора СЯ максимально быстро и дешево.
Критерии выбора конкурента:
- не агрегатор;
- не сайты сервисов;
сайт по типу контента и информации соответствует нашему сайту (если рассматривать наших конкурентов, то хорошую видимость имеет сайт flowwow.com, но при беглом его просмотре мы понимаем, что это вовсе не наш конкурент).

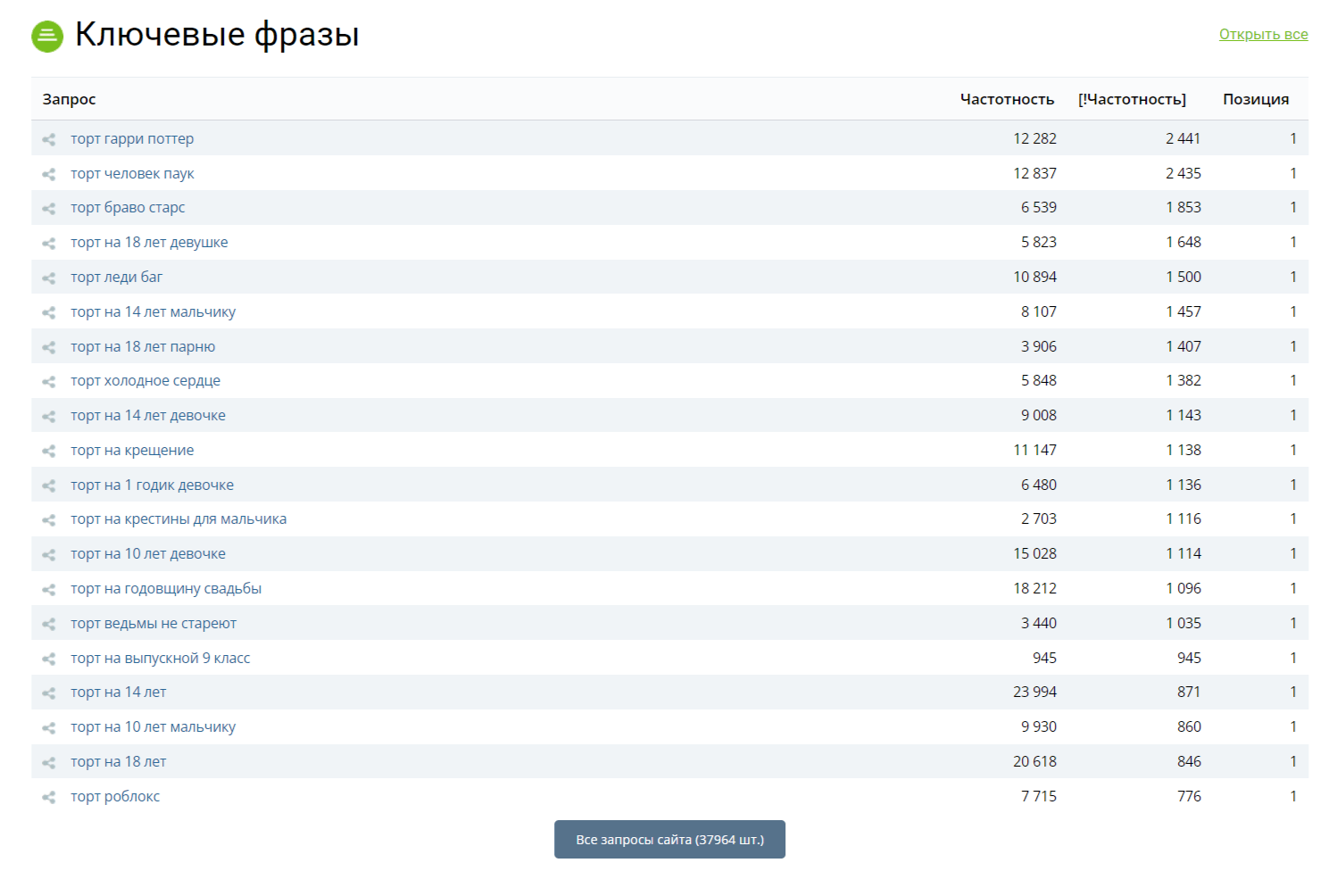
Нас интересует вкладка "ключевые фразы". Нажимаем на количество запросов и переходим на страницу с ключами, по которым конкурент имеет видимость. Мы с вами получили файл, в котором 37 000+ запросов нашей тематики.
Плюсы данного метода сбора семантики:
- мы собираем семантику сайта, который имеет большую видимость, следовательно имеет ключевые фразы, по которым пользователи действительно ищут те или иные торты (в нашем случае);
- все данные в одной таблице – можно сортировать по любым параметрам;
- сразу есть частотности, с которыми можно работать;
- есть релевантные страницы, которые в дальнейшем можно проанализировать.
Делаем выгрузку файла, который мы получили с помощью кейсо. Далее у нас идет этап чистки.
Как почистить семантику
Поскольку тематика коммерческая, то, как правило, есть 2 формата поискового спроса: трафик с категорий, трафик с категорий + товары. В данном случае мы не берем в расчет информационный трафик.
Проанализировав структуру конкурента, мы видим, что все категории в url имеют вложенность /torty/.
Через фильтры мы выбираем поле "страница" и параметр, чтобы она содержала интересующую нас часть адреса.

Тем самым мы сократили нашу семантику до 35 000 запросов.
Далее мы сортируем по позициям. Так как мы выбрали конкурента, который давно уже стоит в топ 10, то тем самым мы можем спокойно отсечь запросы дальше 20 позиции. Поскольку если сайт хорошо оптимизирован, имеет большую видимость и посещаемость, то нас не интересуют запросы, которые не продвинулись.
Если видим, что получилось много ключей и хотим сократить работу, то смело режем по топ-10, что я и сделал в нашем файле. В итоге у нас получилось 21 000 ключевых фраз.
Далее нам необходимо убрать общие минус слова, такие как:
- авито;
- яндекс;
- фото (в нашей тематике такая добавка означает информационный характер ключа);
- картинки (как и выше);
- ru (так как это добавка означает наличие в запросе адреса конкурента);
- другие слова.
После удаления ненужных слова у нас осталось 17 600 запросов. То есть мы за пару минут сократили семантику вдвое, но при этом остались только запросы, на которые реально есть спрос.
Следующий этап чистки семантического ядра – поиск часто повторяющихся слов, которые нам не нужны. Поскольку идея статьи "как не разориться при сборе семантики", то предполагается, что у нас нет key kollectora. Поэтому берем наши ключевые слова и идем в бесплатный сервис advego.com. Только помним про ограничение на 100 000 символов.
Разбив часть семантики на слова, можно выявить те, которые точно не подходят для нас.

Таким образом мы нашли слова:
- надпись;
- прикольные;
- идеи;
- оформление;
- смешной.
Далее не забываем удалить страницы пагинации или страницы с параметрами, так как, скорее всего, они получили видимость по ошибке.
Приводим наш файл к нормальному виду, сделав 2 сортировки: сначала по убыванию по точной частоте, потом сортировка от А до Я по странице. По сути наша семантика готова, на это мы потратили не более 30 минут. Далее советуем поставить плагин SEO-exel. Выделяем столбец с адресом страницы и красим столбцы.
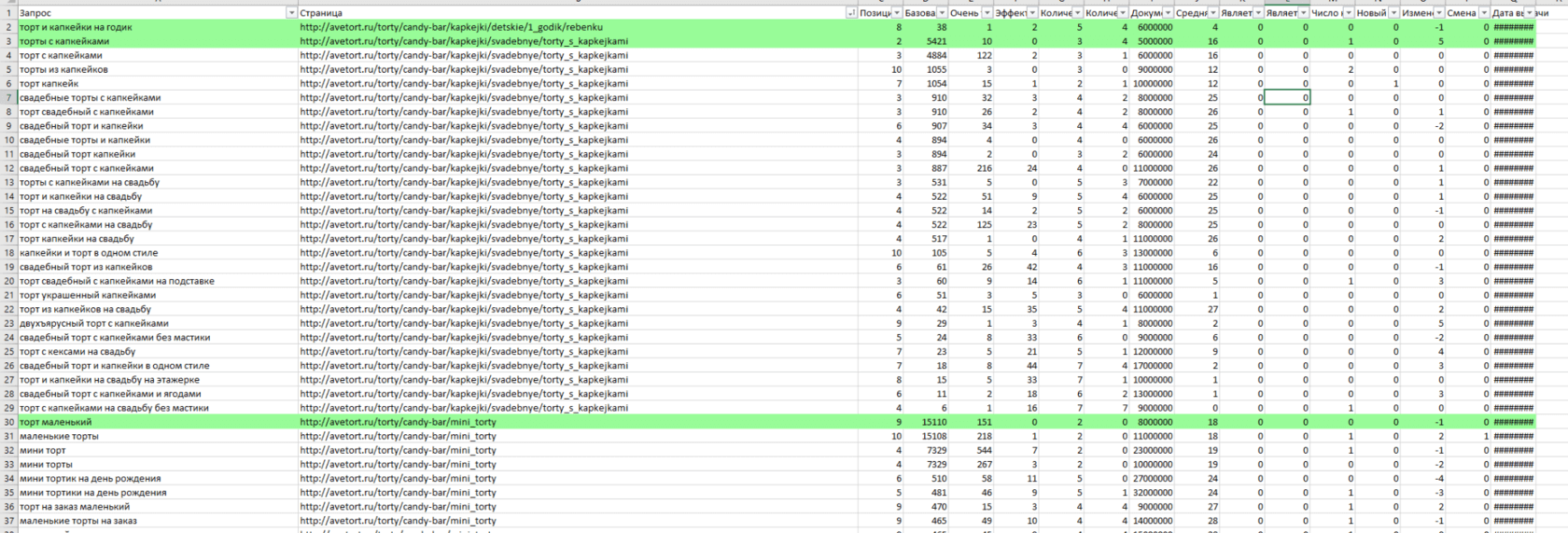
Дальнейшая работа с файлом с семантикой
Чтобы понять, как использовать семантическое ядро, надо вернуться еще раз в начало статьи и вспомнить, что семантика является фундаментом построения сайта. Так как на основе семантики строится структура, создаются новые страницы (оптимизируются старые), пишутся метатеги.
И для дальнейшей работы очень удобен файл, представляющий собой дорожную карту работы с семантикой. Мы его постоянно используем в работе в нашем агентстве.
Вот наш файл, который получился в результате совместной работы за 1 вечер. Мы имеем 16 153 очищенных запроса и 1917 групп для внедрения.

На третьей вкладке отображается наша маркерная структура, которую можно проанализировать, изучить и внедрить.
Правильно подобрав конкурента с хорошей структурой, мы сразу получаем нужную нам вложенность категорий. Например, /detskie/ – мы видим закономерность в адресах, а следовательно, это полная категория "Детские торты." Мы за полчаса работы получили 613 подкатегорий для категории детские торты. Которые в свою очередь также разбиты на подкатегории:
- для мальчиков;
- для девочек;
- для малышей;
- по возрасту;
- и т.д.
Если бы мы все делали это по старинке — парсинг вордстата, подсказок, выгрузки конкурентов, парсинг букварикс, кластеризация, чистка —мы бы потратили уйму времени. Плюс необходимы программы для работы данным методом. А в связи с последними изменениями в работе парсинга KEY KOLEKTORA (необходимость трастовых профилей, проксей, постоянная капча) ушло бы еще и огромное количество денег.
- Семантика простыми словами
- Как составить семантическое ядро
- Итак, давайте начнем
- Критерии выбора конкурента:
- Плюсы данного метода сбора семантики:
- Как почистить семантику
- Дальнейшая работа с файлом с семантикой